July 14, 2023
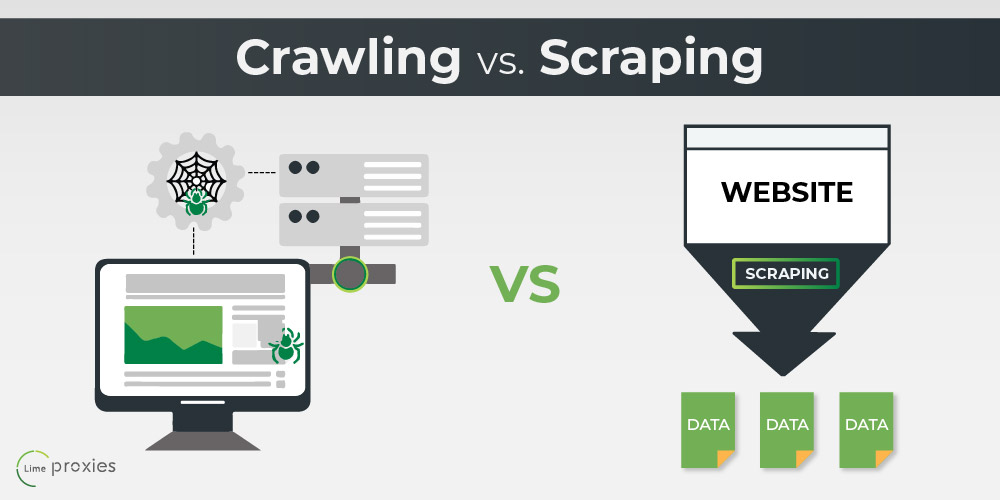
Internet Scraping Vs Web Crawling: Whats The Difference?

Application of a quantitative framework to improve the accuracy of a ... - pnas.org
Application of a quantitative framework to improve the accuracy of a ....
Posted: Mon, 01 May 2023 07:00:00 GMT [source]

Better Analysis
Python can be used for developing websites and also software application, task automation, data analysis, and also data visualization. Find out internet scraping with Ruby with this step-by-step tutorial. We will certainly see the different methods to scrape the internet in Ruby via lots of example with gems like Nokogiri, Kimurai and also HTTParty. Each URL is converted to a request as well as included in the list of demands on our analyzed product. Floki is a collection for parsing as well as controling HTML records, as well as will certainly be used to extract the data from the crawler's result. Free Chrome Web Scraping Services proxy supervisor extension that deals with any proxy carrier.No Matter What Information Kinds You're Searching For, We've Got You Covered
Web scraping is basically drawing out data from websites in an automated fashion. In this write-up, read a description of the differences between internet scuffing and also internet crawling. To remove the data, the data crawler drills deep into the Web. To learn what's relevant to your pursuit, consider spiders or bots scavenging with the Net.- These areas benefit heavily from having accessibility to large data sets to train algorithms as well as develop prediction designs.
- Information scraping entails situating information and after that removing it.
- Remember that using choose or select_one will certainly offer you the entire aspect with the tags consisted of, so we need.text to give us the message between the tags.
Apify Python Api Client
The crawler will get stuck in those pages and get in an unlimited loop. Scraper accesses to the internet site utilizing the IP address appointed by the proxy web server. Internet search engine discover and index your site based upon algorithms that have extremely particular search parameters. A webmaster and also SEO experts ought to deal with the optimization process that would certainly cause growing rankings and raising website traffic, https://www.datahen.com/api-integration-services increasing your web site and also, in turn, your business. However, web scratching can be done manually without the aid of a crawler.What is the distinction in between data scuffing and also information crawling?
Data crawling is a wider process of systematically checking out and indexing information resources, while data scraping is a much more details process of removing targeted information from those resources. Both methods can be made use of with each other to essence data from web sites, databases, or other resources.
Social Links